Recovering a cluster that has lost quorum
During configuration changes, we cannot switch directly from the old configuration to the next, because conflicting majorities could arise. When that happens, no leader can be elected and eventually raft declares the whole cluster as unavailable which leaves it in a hot loop. One way to solve it, is to force the cluster downgrade to a single instance cluster and then gradually introduce new nodes (by scaling up the StatefulSet). With that approach we avoid the need of manual intervention in order to recover a cluster that has lost quorum.
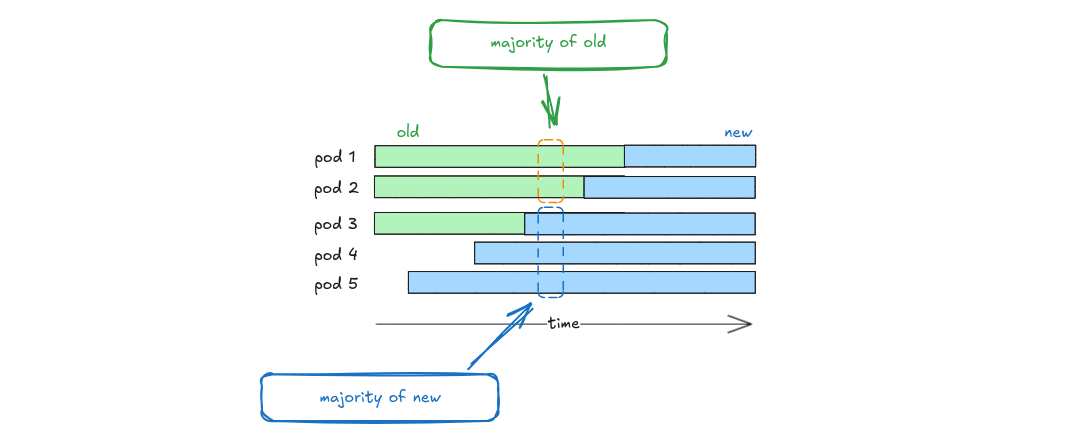
Scaling the StatefulSet down and subsequently (gradually) up, would typically be the manual intervention required to recover a cluster that has lost its quorum. However, the controller automates this process, as long as is not a memory or disk capacity issue, ensuring no service interruption and eliminating the need for any administration action.
Quorum Reconciliation Loop
The quorum reconciler takes the following steps in every term:
-
The quorum reconciler probes each cluster node status endpoint:
http://{nodeUrl}:{api-port}/status. The response looks like this:{"committed_index":1,"queued_writes":0,"state":"LEADER"}statecan be one of the following values:LEADER,FOLLOWER,NOT_READY. Based on the values retrieved for each node, the controller will evaluate the status of the whole cluster which can be:Status Description OK A single LEADERnode was foundSPLIT_BRAIN More than one LEADERs were foundNOT_READY More than the minimum required nodes were in NOT_READYstateELECTION_DEADLOCK No LEADERnode was found -
If the cluster status is evaluated as
SPLIT_BRAIN, it is instantly downgraded to a single-node cluster giving Typesense the chance to try recover a healthy quorum in a fast and reliable fashion. -
For any other cluster status outcome, the quorum reconciler, proceeds to probe each cluster node health endpoint:
http://{nodeUrl}:{api-port}/health. The various response values of this request can be:Response HTTP Status Code Description {ok: true}200The node is healthy and active member of the quorum {ok: false}503The node is unhealthy (various reasons) {ok: false, resource_error: "OUT_OF_{MEMORY/DISK}}503The node requires manual intervention If every single node returns
{ok: true}then the cluster is marked as ready and fully operational. -
If the cluster status is evaluated as
ELECTION_DEADLOCK, it is instantly downgraded to a single-node cluster giving Typesense the chance to try recover a healthy quorum in a fast and reliable fashion. -
- If the cluster status is evaluated as
NOT_READYand it's either a single-node cluster or the healthy evaluated nodes are less than the minimum required nodes (at least(N-1)/2) then the cluster is instantly downgraded to a single-node cluster giving Typesense the chance to try recover a healthy quorum in a fast and reliable fashion, and waits a term before starting the reconciliation again. If nothing of the above conditions are met, then the reconciler proceeds to the next check point: - If the cluster status is evaluated as
OKbut the number of actualStatefulSetreplicas is less than the desired number of replicas specified in thetypesense.specs.replicas, it is upgraded (either instantly or gradually; depends on the value oftypesense.specs.incrementalQuorumRecovery) and restarts the reconciliation after approximately a minute. If none of the conditions above are met, the reconciler proceeds to the next check point: - If the healthy evaluated nodes are less than the minimum required nodes (at least
(N-1)/2), then the cluster is marked as not ready and returns the control back to the reconciler waiting a term till it restarts the reconciliation loop, - If none of these checkpoints led to a restart of the reconciliation loop without a quorum recovery, then the then the cluster is marked as ready and fully operational.
- If the cluster status is evaluated as